

2018年11月26日
理化学研究所
東京大学
1.発表者
| 石田 隆 | 理化学研究所革新知能統合研究センター 不完全情報学習チーム 研修生 |
| Gang Niu | 理化学研究所革新知能統合研究センター 不完全情報学習チーム 研究員 |
| 杉山 将 | 理化学研究所革新知能統合研究センター 不完全情報学習チーム チームリーダー/センター長 |
2.発表概要
理化学研究所(理研)革新知能統合研究センター不完全情報学習チームの石田 隆研修生(東京大学大学院新領域創成科学研究科博士課程)、ガン・ニュー(Gang Niu)研究員、杉山 将チームリーダーの研究チームは、人工知能(AI)[1]を用いた、データを正と負に分ける機械学習[2]の分類問題に対して、正のデータとその信頼度(正信頼度)の情報だけから、分類境界を学習できる手法を開発しました。
本研究成果により、これまで負のデータを収集できないという理由で分類技術が用いられてこなかった多くの分野において、今後、正信頼度の情報に基づく分類技術が適用されると期待できます。
一般に機械学習の分類技術を用いるには、正と負の両方のデータを収集する必要がありますが、実世界では正のデータしか手に入らず、負のデータを収集できない場合が多くあります。例えば、購買予測では、顧客が過去に自社商品を購入した例(正のデータ)は集められますが、ライバル商品を購入した例(負のデータ)は集められません。このような分類問題に対して、従来の分類技術ではコンピュータは学習できませんでした。今回、研究チームは、たとえ正のデータしかなくても、それに対する信頼度(正信頼度)の情報さえあれば、分類境界を学習できることを示しました。
本研究は、モントリオール(カナダ)で開催される機械学習の国際会議「Neural Information Processing Systems(NeurIPS 2018)」(12月3日より)での発表に先立ち、NeurIPS 2018のウェブサイトにて公開(11月23日)されました。
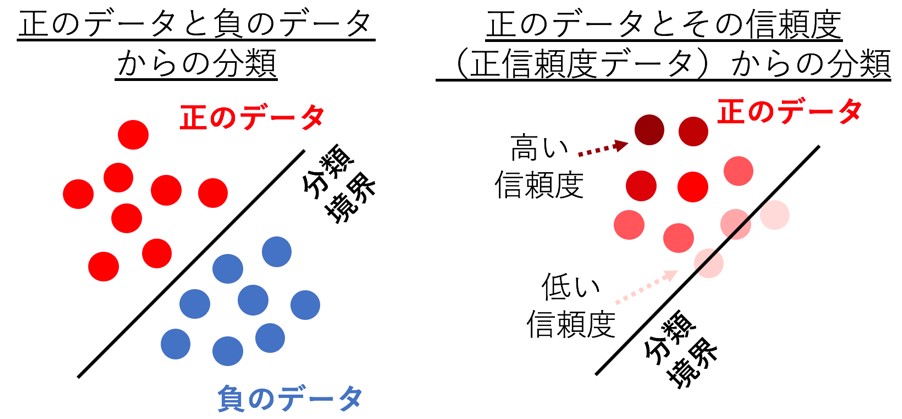
図 通常の分類問題(左)と本研究が対象とする分類問題(右)を表した概念
※研究支援
石田 隆研修生(東京大学大学院新領域創成科学研究科博士課程)は、三井住友アセットマネジメントより博士課程の支援を受けました。
3.背景
人工知能(AI)を用いた機械学習の分類問題に対しては、正のデータと負のデータを分離する境界をコンピュータに学習させます。一度そのような分類境界を学習すれば、未知のデータに対しても、それが正なのか負なのかをコンピュータが判断できるようになります(図1)。
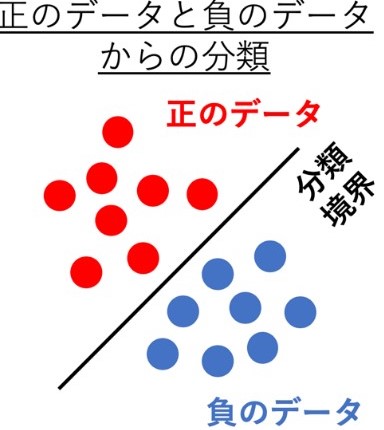
図1 通常の分類問題を表した概念図
コンピュータは、収集された正と負の両方のデータによって分類境界を学習する。
分類技術は、社会実装が最も進んでいる機械学習の一つであり、迷惑メール検知、文章の意味合いがポジティブかネガティブかの判定、写真の人物予測などに利用されてきました。近年では、自動運転車による周囲認識や衛星画像による各国の経済活動推定などにも利用され、ますます広がりを見せています。
従来の分類技術は、正のデータも負のデータも準備できることを前提にしていますが、この前提が満たされないケースがさまざまな応用の場面で存在します。例えば、顧客が自社商品を購入するのか、ライバル商品を購入するのかを予測するという購買予測では、過去に自社商品を購入した例(正のデータ)は収集できますが、ライバル商品を購入した例(負のデータ)は収集できません。
また、これまで正と負の両方のデータを容易に収集できた分野であっても、今後はその前提が満たされなくなる可能性があります。例えば、スマートフォンアプリ開発会社がアプリユーザーの脱退予測を行う際に、利用継続しているユーザーの例(正のデータ)は収集できますが、過去に脱退したユーザーの例(負のデータ)は削除されて残っていない場合があります。これは、年々厳しくなるデータ関連の規制や、それに伴うユーザー保護のためのプライバシーポリシーの強化などにより起こりえます。近年、情報通信技術業界では、家計簿や決済データ、ヘルスケアや遺伝子解析データなど、その取り扱いに慎重を要する個人データを利用するビジネスモデルが増えつつあります。このようなデータを扱う企業は、ユーザーが自身のデータを削除する権利を保証しなければならない一方で、コンピュータには理想的なデータを与えて高度なサービスを提供したいというジレンマに陥る可能性があります。
そこで研究チームは、正のデータしか手に入らない場合でも「信頼度の情報」さえあれば、コンピュータはうまく学習できるのではないかと考えました。信頼度の情報とは、数学的にはそのデータが正のクラスに属する確率に対応しますが、概念としては「正のデータがどれだけ正のデータらしいか」を示すものです。例えば、購買予測では、過去に自社商品を購入したときの顧客の購買意欲など、アプリユーザーの脱退予測では、非脱退ユーザーのアクティブ率(ユーザーが一定期間にアプリを利用した頻度)などの指標から、信頼度は構成されます。
4.研究手法と成果
正のデータとその信頼度(正信頼度)の情報だけから、分類境界を学習する場合、まずは次のように考えられます。図2では、正のデータしか与えられていませんが、左上のデータは信頼度が高く、右下のデータは信頼度が低いので、直感的には右下側のどこかに分類境界があると想像されます。
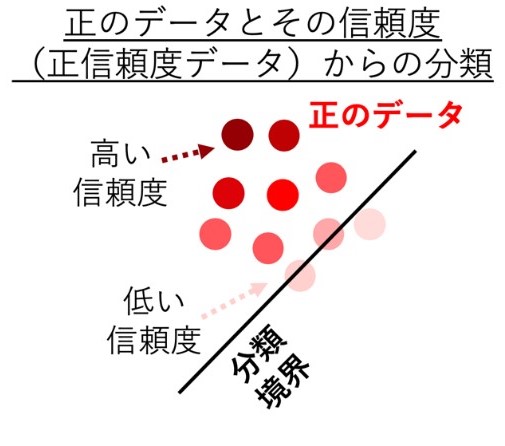
図2 新たな分類を表した概念図
たとえ正のデータしかなくても、その正のデータに対する信頼度(正信頼度)の情報さえあれば、分類境界を学習できる。
このアイデアを学習アルゴリズム[3]に落とし込むには、全てのデータを信頼度に従って、正のデータと負のデータに分解する方法が考えられます。例えば、あるデータの信頼度が90%であれば、それは「正のデータ90%」「負のデータ10%」の重みが付けられたニつのデータ(正と負のデータ)に分解できます。このプロセスを全てのデータに対して行うと、正と負の両方のデータが存在する通常の分類問題の設定と同じになり、従来の学習アルゴリズムが適用できるようになるというわけです。しかしこの方法では、正しい分類境界から離れた位置にある境界をコンピュータが学習してしまうことを、研究チームは理論と実験の研究から明らかにしました。
そこで次に、研究チームは、正と負の両方のデータが存在するときにコンピュータが最小化していた分類リスク[4]の数式について、正のデータとその信頼度のデータで書き直す式変形を行なうことで再構成してみました。その結果、分類リスクが正のデータとその信頼度だけで表現されることを発見しました。この再構成された分類リスクを最小化すれば、正のデータとその信頼度だけから精度良く学習できるようになります(図3)。さらに理論解析により、この方法が統計的に望ましい性質(十分多いデータ数があれば最適な分類器が得られるという一致性など)を持つことを証明しました。
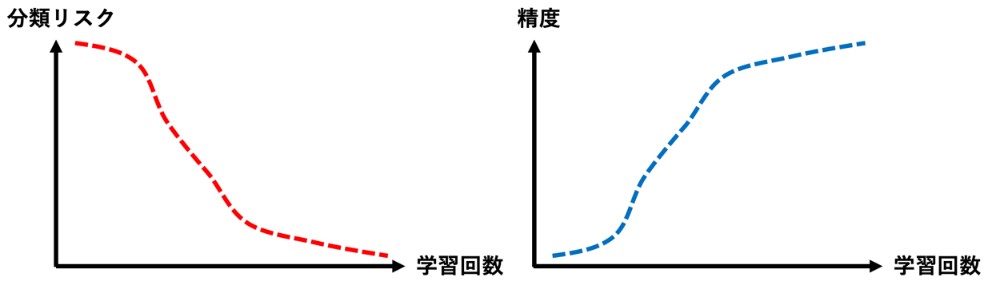
図3 分類リスクと分類精度の関係
分類リスクを最小化するに従い、正のデータとその信頼度からの分類精度は向上する。
このようにして研究チームは、未知データを正と負に分ける機械学習の分類問題に対して、正のデータとその信頼度(正信頼度)の情報だけから、分類境界を学習できる手法の開発に成功しました。開発した学習アルゴリズムは、シンプルな線形モデル[5]や深い構造を持つ深層学習モデル[6]など、あらゆる分類モデルと容易に組み合わせることができます。
さらに、ベンチマーク(基準)となるデータセットを用いた実験により、正のデータとその信頼度だけからコンピュータがうまく学習できることを示しました。本手法は、ほかの手法(正のデータだけを与えて負のデータを察知する異常検知の手法、正のデータの信頼度を直接予測する回帰に基づく手法、前述の重み付け手法)と比較して、大多数のデータセットに対して最も良い分類精度を示すことが分かりました。
5.今後の期待
今後、これまで負のデータを収集できないという理由で分類技術が用いられてこなかった多くの分野において、正信頼度の情報に基づく分類技術が適用されると期待できます。また、分類技術は自然言語処理[7]、コンピュータビジョン[8]、ロボティクス、バイオインフォマティクス[9]などさまざまな研究分野で活用されていることから、「正信頼度からの分類」に対してもさまざまな応用研究が行なわれると考えられます。そのために、実験で使用したプログラミング言語Python(パイソン)によるアルゴリズムの実装コードをウェブ上で公開する予定です。
6.発表情報
タイトル:Binary Classification from Positive-Confidence Data
発表者名:Takashi Ishida, Gang Niu, Masashi Sugiyama
学会名:Neural Information Processing Systems (NeurIPS 2018)

左から杉山 将、石田 隆、Gang Niu
7.補足説明
[1] 人工知能(AI)
コンピュータ上などで人間と同様の知能を人工的に実現させようという試み、あるいは技術を指す。人工知能にはさまざまな基礎技術が用いられているが、その重要な技術の一つとして機械学習が位置づけられている。AIはartificial intelligenceの略。
[2] 機械学習
データから有用な情報、知識、規則をコンピュータが抽出する技術の総称。機械学習の中でも、入力データと出力(答え)が与えられる問題設定を「教師あり学習」と呼び、入力データだけが与えられる問題設定を「教師なし学習」と呼ぶ。本研究の「正信頼度データからの分類」は、負のデータにアクセスできないという制約があり、両者の中間的設定「弱教師あり学習」として位置づけることができる。
[3] アルゴリズム
機械(コンピュータ)において、特定の目的を達成させるために必要な情報処理の方法や手順のこと。
[4] 分類リスク
あるデータに対する分類器の予測とそのデータの実際の出力(答え)を比較し、その誤差を考える関数を損失関数と呼ぶ。損失関数の期待値を取った値を分類リスクと呼ぶ。
[5] 線形モデル
d次元の入力データxに対して、d次元のパラメータwをかけ合わせたw∙xを出力とするモデル。入力と出力が線形の関係になるため、線形モデルと呼ぶ。
[6] 深層学習モデル
入力と出力が線形ではない非線形モデルの一種としてニューラルネットワークモデルがあり、中でもニューラルネットワークを多層的に組み合わせた深い構造を持つモデルを、深層学習モデルと呼ぶ。
[7] 自然言語処理
コンピュータによって人間の言語である日本語や英語などを処理、分析、理解しようと試みる研究分野。機械翻訳、要約、文章生成、質問応答など多岐にわたる研究が活発に行われている。
[8] コンピュータビジョン
コンピュータによって画像や動画を処理、分析、理解しようと試みる研究分野。物体認識、動作認識、イベント検知、セグメンテーション、キャプション生成、画像生成など多岐にわたる研究が活発に行われている。
[9] バイオインフォマティクス
生物学と情報学の融合分野で、DNAやRNA、タンパク質など発現や機能に関する生命現象を情報科学や統計学などのアルゴリズムを用いて分析する研究分野。
7.問い合わせ先
<研究内容について>
理化学研究所 革新知能統合研究センター 広報担当
E-mail:aip-koho[at]riken.jp
<機関窓口>
理化学研究所 広報室 報道担当
TEL:048-467-9272 FAX:048-462-4715
E-mail:ex-press[at]riken.jp
東京大学 大学院新領域創成科学研究科 総務係
TEL:04-7136-5578 FAX:04-7136-4020
※上記の[at]は@に置き換えてください。
掲載情報
Science Daily (11/26)、PHYS.ORG(11/26)、日刊工業新聞(11/28)、SciTech EUROPA (11/28)、化学工業日報(12/7)、ASIAN SCIENTIST(12/8)、ISE Magazine (Volume.51, January 2019)
<プレスリリース>


